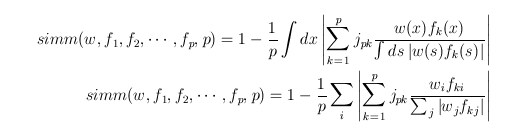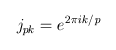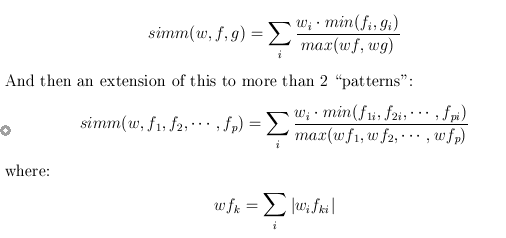Now, define our spike waves using the range function (NB: the last term in the range function is the step size):
spikes |wave-1> => range(|0>,|1000>,|1>) spikes |wave-2> => range(|0>,|1000>,|2>) spikes |wave-3> => range(|0>,|1000>,|3>) spikes |wave-4> => range(|0>,|1000>,|4>) spikes |wave-5> => range(|0>,|1000>,|5>) spikes |wave-6> => range(|0>,|1000>,|6>) spikes |wave-7> => range(|0>,|1000>,|7>) spikes |wave-8> => range(|0>,|1000>,|8>) spikes |wave-9> => range(|0>,|1000>,|9>) spikes |wave-10> => range(|0>,|1000>,|10>) spikes |wave-11> => range(|0>,|1000>,|11>) spikes |wave-12> => range(|0>,|1000>,|12>) spikes |wave-13> => range(|0>,|1000>,|13>) spikes |wave-14> => range(|0>,|1000>,|14>) spikes |wave-15> => range(|0>,|1000>,|15>) spikes |wave-16> => range(|0>,|1000>,|16>) spikes |wave-17> => range(|0>,|1000>,|17>) spikes |wave-18> => range(|0>,|1000>,|18>) spikes |wave-19> => range(|0>,|1000>,|19>) spikes |wave-20> => range(|0>,|1000>,|20>) spikes |empty> => 0 spikes |wave-1>And a couple of operators to examine this knowledge:
show-spike-wave |*> #=> bar-chart[50] select[1,30] ket-sort spikes (|empty> + |_self>) show-similarity |*> #=> bar-chart[50] ket-sort similar-input[spikes] spikes |_self>Let's visualize our spike waves:
sa: show-spike-wave |wave-1> ---------- 0 : |||||||||||||||||||||||||||||||||||||||||||||||||| 1 : |||||||||||||||||||||||||||||||||||||||||||||||||| 2 : |||||||||||||||||||||||||||||||||||||||||||||||||| 3 : |||||||||||||||||||||||||||||||||||||||||||||||||| 4 : |||||||||||||||||||||||||||||||||||||||||||||||||| 5 : |||||||||||||||||||||||||||||||||||||||||||||||||| 6 : |||||||||||||||||||||||||||||||||||||||||||||||||| 7 : |||||||||||||||||||||||||||||||||||||||||||||||||| 8 : |||||||||||||||||||||||||||||||||||||||||||||||||| 9 : |||||||||||||||||||||||||||||||||||||||||||||||||| 10 : |||||||||||||||||||||||||||||||||||||||||||||||||| 11 : |||||||||||||||||||||||||||||||||||||||||||||||||| 12 : |||||||||||||||||||||||||||||||||||||||||||||||||| 13 : |||||||||||||||||||||||||||||||||||||||||||||||||| 14 : |||||||||||||||||||||||||||||||||||||||||||||||||| 15 : |||||||||||||||||||||||||||||||||||||||||||||||||| 16 : |||||||||||||||||||||||||||||||||||||||||||||||||| 17 : |||||||||||||||||||||||||||||||||||||||||||||||||| 18 : |||||||||||||||||||||||||||||||||||||||||||||||||| 19 : |||||||||||||||||||||||||||||||||||||||||||||||||| 20 : |||||||||||||||||||||||||||||||||||||||||||||||||| 21 : |||||||||||||||||||||||||||||||||||||||||||||||||| 22 : |||||||||||||||||||||||||||||||||||||||||||||||||| 23 : |||||||||||||||||||||||||||||||||||||||||||||||||| 24 : |||||||||||||||||||||||||||||||||||||||||||||||||| 25 : |||||||||||||||||||||||||||||||||||||||||||||||||| 26 : |||||||||||||||||||||||||||||||||||||||||||||||||| 27 : |||||||||||||||||||||||||||||||||||||||||||||||||| 28 : |||||||||||||||||||||||||||||||||||||||||||||||||| 29 : |||||||||||||||||||||||||||||||||||||||||||||||||| ---------- |bar chart> sa: show-spike-wave |wave-2> ---------- 0 : |||||||||||||||||||||||||||||||||||||||||||||||||| 1 : 2 : |||||||||||||||||||||||||||||||||||||||||||||||||| 3 : 4 : |||||||||||||||||||||||||||||||||||||||||||||||||| 5 : 6 : |||||||||||||||||||||||||||||||||||||||||||||||||| 7 : 8 : |||||||||||||||||||||||||||||||||||||||||||||||||| 9 : 10 : |||||||||||||||||||||||||||||||||||||||||||||||||| 11 : 12 : |||||||||||||||||||||||||||||||||||||||||||||||||| 13 : 14 : |||||||||||||||||||||||||||||||||||||||||||||||||| 15 : 16 : |||||||||||||||||||||||||||||||||||||||||||||||||| 17 : 18 : |||||||||||||||||||||||||||||||||||||||||||||||||| 19 : 20 : |||||||||||||||||||||||||||||||||||||||||||||||||| 21 : 22 : |||||||||||||||||||||||||||||||||||||||||||||||||| 23 : 24 : |||||||||||||||||||||||||||||||||||||||||||||||||| 25 : 26 : |||||||||||||||||||||||||||||||||||||||||||||||||| 27 : 28 : |||||||||||||||||||||||||||||||||||||||||||||||||| 29 : ---------- |bar chart> sa: show-spike-wave |wave-3> ---------- 0 : |||||||||||||||||||||||||||||||||||||||||||||||||| 1 : 2 : 3 : |||||||||||||||||||||||||||||||||||||||||||||||||| 4 : 5 : 6 : |||||||||||||||||||||||||||||||||||||||||||||||||| 7 : 8 : 9 : |||||||||||||||||||||||||||||||||||||||||||||||||| 10 : 11 : 12 : |||||||||||||||||||||||||||||||||||||||||||||||||| 13 : 14 : 15 : |||||||||||||||||||||||||||||||||||||||||||||||||| 16 : 17 : 18 : |||||||||||||||||||||||||||||||||||||||||||||||||| 19 : 20 : 21 : |||||||||||||||||||||||||||||||||||||||||||||||||| 22 : 23 : 24 : |||||||||||||||||||||||||||||||||||||||||||||||||| 25 : 26 : 27 : |||||||||||||||||||||||||||||||||||||||||||||||||| 28 : 29 : ---------- |bar chart> sa: show-spike-wave |wave-7> ---------- 0 : |||||||||||||||||||||||||||||||||||||||||||||||||| 1 : 2 : 3 : 4 : 5 : 6 : 7 : |||||||||||||||||||||||||||||||||||||||||||||||||| 8 : 9 : 10 : 11 : 12 : 13 : 14 : |||||||||||||||||||||||||||||||||||||||||||||||||| 15 : 16 : 17 : 18 : 19 : 20 : 21 : |||||||||||||||||||||||||||||||||||||||||||||||||| 22 : 23 : 24 : 25 : 26 : 27 : 28 : |||||||||||||||||||||||||||||||||||||||||||||||||| 29 : ---------- |bar chart>Now the interesting bit, visualizing their similarity:
sa: show-similarity |wave-1> ---------- wave-1 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-2 : ||||||||||||||||||||||||| wave-3 : |||||||||||||||| wave-4 : |||||||||||| wave-5 : |||||||||| wave-6 : |||||||| wave-7 : ||||||| wave-8 : |||||| wave-9 : ||||| wave-10 : ||||| wave-11 : |||| wave-12 : |||| wave-13 : ||| wave-14 : ||| wave-15 : ||| wave-16 : ||| wave-17 : || wave-18 : || wave-19 : || wave-20 : || ---------- |bar chart> sa: show-similarity |wave-2> ---------- wave-1 : ||||||||||||||||||||||||| wave-2 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-3 : |||||||||||||||| wave-4 : ||||||||||||||||||||||||| wave-5 : |||||||||| wave-6 : |||||||||||||||| wave-7 : ||||||| wave-8 : |||||||||||| wave-9 : ||||| wave-10 : |||||||||| wave-11 : |||| wave-12 : |||||||| wave-13 : ||| wave-14 : ||||||| wave-15 : ||| wave-16 : |||||| wave-17 : || wave-18 : ||||| wave-19 : || wave-20 : ||||| ---------- |bar chart> sa: show-similarity |wave-3> ---------- wave-1 : |||||||||||||||| wave-2 : |||||||||||||||| wave-3 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-4 : |||||||||||| wave-5 : |||||||||| wave-6 : ||||||||||||||||||||||||| wave-7 : ||||||| wave-8 : |||||| wave-9 : |||||||||||||||| wave-10 : ||||| wave-11 : |||| wave-12 : |||||||||||| wave-13 : ||| wave-14 : ||| wave-15 : |||||||||| wave-16 : ||| wave-17 : || wave-18 : |||||||| wave-19 : || wave-20 : || ---------- |bar chart> sa: show-similarity |wave-4> ---------- wave-1 : |||||||||||| wave-2 : ||||||||||||||||||||||||| wave-3 : |||||||||||| wave-4 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-5 : |||||||||| wave-6 : |||||||||||||||| wave-7 : ||||||| wave-8 : ||||||||||||||||||||||||| wave-9 : ||||| wave-10 : |||||||||| wave-11 : |||| wave-12 : |||||||||||||||| wave-13 : ||| wave-14 : ||||||| wave-15 : ||| wave-16 : |||||||||||| wave-17 : || wave-18 : ||||| wave-19 : || wave-20 : |||||||||| ---------- |bar chart> sa: show-similarity |wave-5> ---------- wave-1 : |||||||||| wave-2 : |||||||||| wave-3 : |||||||||| wave-4 : |||||||||| wave-5 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-6 : |||||||| wave-7 : ||||||| wave-8 : |||||| wave-9 : ||||| wave-10 : ||||||||||||||||||||||||| wave-11 : |||| wave-12 : |||| wave-13 : ||| wave-14 : ||| wave-15 : |||||||||||||||| wave-16 : ||| wave-17 : || wave-18 : || wave-19 : || wave-20 : |||||||||||| ---------- |bar chart> sa: show-similarity |wave-6> ---------- wave-1 : |||||||| wave-2 : |||||||||||||||| wave-3 : ||||||||||||||||||||||||| wave-4 : |||||||||||||||| wave-5 : |||||||| wave-6 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-7 : ||||||| wave-8 : |||||||||||| wave-9 : |||||||||||||||| wave-10 : |||||||||| wave-11 : |||| wave-12 : ||||||||||||||||||||||||| wave-13 : ||| wave-14 : ||||||| wave-15 : |||||||||| wave-16 : |||||| wave-17 : || wave-18 : |||||||||||||||| wave-19 : || wave-20 : ||||| ---------- |bar chart> sa: show-similarity |wave-7> ---------- wave-1 : ||||||| wave-2 : ||||||| wave-3 : ||||||| wave-4 : ||||||| wave-5 : ||||||| wave-6 : ||||||| wave-7 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-8 : |||||| wave-9 : ||||| wave-10 : ||||| wave-11 : |||| wave-12 : |||| wave-13 : ||| wave-14 : ||||||||||||||||||||||||| wave-15 : ||| wave-16 : ||| wave-17 : ||| wave-18 : || wave-19 : || wave-20 : || ---------- |bar chart> sa: show-similarity |wave-8> ---------- wave-1 : |||||| wave-2 : |||||||||||| wave-3 : |||||| wave-4 : ||||||||||||||||||||||||| wave-5 : |||||| wave-6 : |||||||||||| wave-7 : |||||| wave-8 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-9 : ||||| wave-10 : |||||||||| wave-11 : |||| wave-12 : |||||||||||||||| wave-13 : ||| wave-14 : ||||||| wave-15 : ||| wave-16 : ||||||||||||||||||||||||| wave-17 : ||| wave-18 : ||||| wave-19 : || wave-20 : |||||||||| ---------- |bar chart> sa: show-similarity |wave-9> ---------- wave-1 : ||||| wave-2 : ||||| wave-3 : |||||||||||||||| wave-4 : ||||| wave-5 : ||||| wave-6 : |||||||||||||||| wave-7 : ||||| wave-8 : ||||| wave-9 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-10 : ||||| wave-11 : |||| wave-12 : |||||||||||| wave-13 : |||| wave-14 : ||| wave-15 : |||||||||| wave-16 : ||| wave-17 : ||| wave-18 : ||||||||||||||||||||||||| wave-19 : || wave-20 : || ---------- |bar chart> sa: show-similarity |wave-10> ---------- wave-1 : ||||| wave-2 : |||||||||| wave-3 : ||||| wave-4 : |||||||||| wave-5 : ||||||||||||||||||||||||| wave-6 : |||||||||| wave-7 : ||||| wave-8 : |||||||||| wave-9 : ||||| wave-10 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-11 : |||| wave-12 : |||||||| wave-13 : ||| wave-14 : ||||||| wave-15 : |||||||||||||||| wave-16 : |||||| wave-17 : || wave-18 : ||||| wave-19 : || wave-20 : ||||||||||||||||||||||||| ---------- |bar chart> sa: show-similarity |wave-11> ---------- wave-1 : |||| wave-2 : |||| wave-3 : |||| wave-4 : |||| wave-5 : |||| wave-6 : |||| wave-7 : |||| wave-8 : |||| wave-9 : |||| wave-10 : |||| wave-11 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-12 : |||| wave-13 : ||| wave-14 : ||| wave-15 : ||| wave-16 : ||| wave-17 : ||| wave-18 : ||| wave-19 : || wave-20 : || ---------- |bar chart> sa: show-similarity |wave-12> ---------- wave-1 : |||| wave-2 : |||||||| wave-3 : |||||||||||| wave-4 : |||||||||||||||| wave-5 : |||| wave-6 : ||||||||||||||||||||||||| wave-7 : |||| wave-8 : |||||||||||||||| wave-9 : |||||||||||| wave-10 : |||||||| wave-11 : |||| wave-12 : |||||||||||||||||||||||||||||||||||||||||||||||||| wave-13 : |||| wave-14 : ||||||| wave-15 : |||||||||| wave-16 : |||||||||||| wave-17 : || wave-18 : |||||||||||||||| wave-19 : || wave-20 : |||||||||| ---------- |bar chart>Now some notes:
1) signals from primes are very strong in these similarity graphs! Prime waves have very low similarity with other waves, and non-prime waves have very high similarity with waves that share factors. eg, wave-11 has very low similarity with the other 19 waves, though it is non-zero because of the initial spike at 0. And wave-12 has high similarity with {6,4,8,18,3,9,16,...} in that order. And very low similarity with {5,7,11,13,17,19}.
2) technically these are spatial waves, not time sequences of spikes since they are superpositions not sequences. I presume, but haven't given it much thought, that the brain can easily convert a time sequence of spikes into a spatial spike wave. Alternatively I should finally find a similarity measure for sequences, not just the current superposition version.
3) perhaps one use for this "spike Fourier transform" would be to convert some arbitrary spike pattern into its frequency (ie, wave-k) components. Though I don't currently know of a concrete use for this. Certainly our ears do a type of Fourier transform, but I think that is a physical thing using vibrating hairs, not a neuron processing thing.
4) I wonder if something similar can be used to measure distances between spikes? If we line it up so the starting spike is at zero, then if there is a spike at time k later, the wave-k neuron should activate. One possible application of measuring distances, but there are many others, would be when analysing a face. ie, distances between the various features in faces as a nice object to superposition mapping.
5) presumably this has some relevance to music.
6) note, the above version is very exacting. The spikes must be exactly integers, else you get no match. Consider steps of size 9.9, and hoping it has some similarity with step size 10:
sa: spikes |wave-9.9> => range(|0>,|1000>,|9.9>) sa: show-similarity |wave-9.9> ---------- wave-9.9 : |||||||||||||||||||||||||||||||||||||||||||||||||| ---------- |bar chart>ie, 0 similarity with our integer spikes. If we don't want that behaviour then we need to smooth our spike transforms. Let's call that a "smoothed spike Fourier transform". This post is too long, so let's do that in a new post.
7) the idea should carry over in an obvious way to spike trains that are not perfectly periodic. Periodic spike trains are just the simplest to consider, because they are so easy to define using the range function, and have the most in common with standard Fourier transforms.