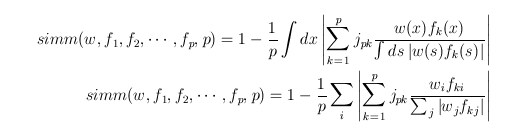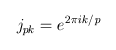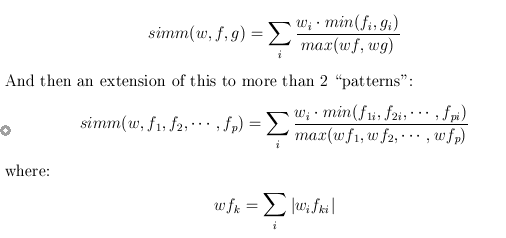OK. A really cool one today! Previously I had discovered that out-going links on wikipedia pages don't share the semantic similarity that you might expect. But usefully for us, in going links do. And this is a very strong effect, as we will see below, and the whole point of this post. Unfortunately doing this all in the console was painfully slow, even after optimizing the superposition simm by a factor of 50 (yeah, cool right!). So the console told me roughly what algo I needed, but I had to implement it elsewhere. Hence:
create-wikivec.py and
wikivec-similarity.py.
The create-wikivec.py code corresponds closely to this code:
sa: load 30k--wikipedia-links.sw
sa: find-inverse[links-to]
sa: hash-op |*> #=> hash[6] inverse-links-to |_self>
sa: map[hash-op,wikivec] rel-kets[inverse-links-to]
sa: save 30k--wikivec.sw
Interestingly, this is 5 lines of code vs roughly 110 in
create-wikivec.py. Though create-wikivec.py pays that work off by being efficient enough to even find
300k--wikivec.sw.
$ ./create-wikivec.py sw-examples/300k--wikipedia-links.sw
Here are a couple of example learn rules in 300k--wikivec.sw:
wikivec |Adelaide_University> => |a6cf5f> + |be49ce> + |35cd3f> + |d96f29> + |ca656e> + |42f440> + |62b8b7>
wikivec |Adelaide,_South_Australia> => |63c9f6> + |c8e53e> + |9c3bfb> + |ae043c> + |4dcb61> + |d225b1> + |b09b3c> + |e66ecf> + |416586> + |7db43d> + |ab0cf1> + |9f14fe> + |9fdf79> + |315616> + |e6e424> + |4044ae> + |a20820> + |e48b2d> + |7a653a> + |6ac327> + |9b981d> + |2d6521> + |8cc4c4> + |914bf6> + |242091>
wikivec |Flinders_University> => |b8d999> + |788f0d> + |e40813> + |c88e1f> + |f04795> + |4cdeb5> + |6f7024> + |f324ae> + |410fc8> + |6adddf> + |315616> + |be9aaa> + |23c003> + |2c0a36> + |46f87c> + |00bef3> + |35cd3f> + |9c55f4> + |71fd70> + |d96f29> + |e971e6> + |f7fb89> + |458567> + |5fe8a1> + |250dc5> + |8e082a> + |049619>
Now, what is the usefulness of wikivec? Well, it has the interesting property of semantic similarity. You enter in a wikipage, and you get out semantically similar wikipages.
Let's give some examples:
$ ./wikivec-similarity.py 'Richard Feynman'
----------------
wikipage: Richard_Feynman
pattern: |bc5f69> + |21188d> + |598f2b> + |4d7b53> + |d0bb87> + |4d30e1> + |e1c298> + |c50e18> + |535935> + |035c48> + |8a5907> + |dbe144> + |5e9c7f> + |8f25ec> + |0166e5> + |89780b> + |eb246d> + |cb6c0b> + |6a31a1> + |cf200e> + |3c1344> + |3dc31c> + |c31b08> + |6f6073> + |1f771c> + |3c8903> + |0bbb4a> + |c01cf3> + |c1b9b6> + |3dfbb4> + |c6c9ea> + |d85395> + |1266a1> + |0ff36f> + |83c6e6> + |6267c4> + |ff4a40> + |3a535a> + |ede342> + |b5cb0d> + |b34209> + |daaf19> + |880c95> + |5286a9> + |3cb0ba> + |93fe8e> + |d8cd9f> + |6582a8> + |44f9a7> + |f97758> + |7ef2ca> + |411fde> + |89385c> + |ff3f25> + |95a2c2> + |2a092d> + |bea185> + |8d9817> + |1093a0> + |00554e> + |a2b605> + |362c5f> + |3c9704> + |38ed16> + |6c1d88> + |42f6b0> + |4a7e62> + |bbcfea> + |c1d4ac> + |a3cf59> + |0a228a> + |9357f7> + |cb12a0> + |581cff> + |2a9cc1> + |4552fc> + |21eb3c> + |77caf9> + |7ed689>
pattern length: 79
----------------
1 Richard_Feynman 100.0
2 Werner_Heisenberg 24.39
3 special_relativity 20.79
4 Niels_Bohr 20.25
5 Paul_Dirac 20.25
6 particle_physics 20.22
7 classical_mechanics 20.0
8 fermion 18.99
9 spin_(physics) 18.99
10 Standard_Model 17.72
11 quantum_field_theory 17.72
12 Schrdinger_equation 17.72
13 electromagnetism 17.24
14 Pauli_exclusion_principle 16.46
15 Julian_Schwinger 16.46
16 Erwin_Schrdinger 16.46
17 quark 16.46
18 Stephen_Hawking 16.46
19 quantum_electrodynamics 16.46
20 Category:Concepts_in_physics 16.28
21 statistical_mechanics 15.19
22 Enrico_Fermi 15.19
23 Dirac_equation 15.19
24 Max_Planck 15.19
25 matter 15.09
26 photon 14.19
27 general_relativity 14.17
28 thermodynamics 14.13
29 photoelectric_effect 13.92
30 Max_Born 13.92
Enter table row number, or wikipage: Stephen_Hawking
----------------
wikipage: Stephen_Hawking
pattern: |ea507a> + |10f49f> + |ea5ab5> + |c5b981> + |a7822a> + |4b4d7e> + |31d840> + |811950> + |0f5ef5> + |f3ceb4> + |3a2d42> + |a97ca0> + |e06e72> + |4cf7a5> + |7b8d5f> + |ff3f25> + |6d8404> + |3dfbb4> + |4d1323> + |f9ebe8> + |54060b> + |b0de39> + |6f6073> + |745049> + |a077a1> + |f4e699> + |8978b1> + |c1b9b6> + |0166e5> + |4a7e62> + |5853ee> + |4552fc> + |7bd69d> + |c266af> + |abfdf5> + |c27486> + |5ba8b0> + |d21237> + |cc5274> + |b6baba> + |483336> + |b5cb0d> + |5eca63> + |ab8f77> + |d43833> + |d17d5d> + |635adb> + |9c11b5> + |ffd306> + |7ef2ca> + |8ca453> + |8f25ec> + |dbe144> + |6187c8> + |df0825> + |9795ef> + |8d5d02> + |880c95> + |3e34b6> + |6681d0> + |b9de4b> + |ad5b5d> + |c54116> + |cdc8cb> + |bbcfea> + |1209bc> + |798fe0> + |3f31b3> + |92603f> + |cffb3d> + |f41208> + |8a4178> + |2b6101>
pattern length: 73
----------------
1 Stephen_Hawking 100.0
2 Roger_Penrose 27.4
3 quantum_gravity 23.29
4 black_hole 22.08
5 string_theory 20.55
6 Big_Bang 20.39
7 spacetime 18.18
8 Universe 17.81
9 general_relativity 17.5
10 Richard_Feynman 16.46
11 cosmology 16.46
12 quantum_field_theory 16.44
13 Niels_Bohr 15.19
14 Standard_Model 15.07
15 John_Archibald_Wheeler 15.07
16 Paul_Dirac 15.07
17 Werner_Heisenberg 14.63
18 Michael_Faraday 14.63
19 particle_physics 14.61
20 electromagnetism 13.79
21 dark_matter 13.7
22 second_law_of_thermodynamics 13.7
23 space 13.7
24 Enrico_Fermi 13.7
25 Erwin_Schrdinger 13.7
26 causality 13.7
27 classical_mechanics 12.94
28 universe 12.5
29 supersymmetry 12.33
30 Steven_Weinberg 12.33
Enter table row number, or wikipage: 4
----------------
wikipage: black_hole
pattern: |c4c39b> + |6a9e58> + |bea185> + |7ef2ca> + |cc5274> + |dbe144> + |291a64> + |205a51> + |8f25ec> + |634f08> + |894281> + |be6128> + |7bd69d> + |a97ca0> + |a8e57c> + |d1445e> + |4d1323> + |1da685> + |be410c> + |b0de39> + |6f6073> + |7ab386> + |91da93> + |d43833> + |81d9b5> + |3a2d42> + |3dfbb4> + |e06e72> + |d8f06f> + |b005aa> + |a12d9e> + |17e6c4> + |db32bc> + |548a4b> + |d23d08> + |2a9cc1> + |cf96ec> + |277acc> + |ec9e16> + |870dd1> + |d51b2d> + |75030e> + |445551> + |ffd306> + |68aced> + |e85f02> + |581cff> + |3e5d6e> + |c62201> + |b4e81b> + |aab465> + |a2fd45> + |70b142> + |89385c> + |343f48> + |df0825> + |cbf57c> + |362c5f> + |3e34b6> + |a5ffc2> + |50345c> + |c403e1> + |bd8415> + |a94489> + |1a3d5b> + |96346d> + |3647b8> + |0cd2d4> + |dba224> + |b9c56b> + |f41208> + |298068> + |067848> + |44ae31> + |71ebb5> + |8bcf88> + |84782a>
pattern length: 77
----------------
1 black_hole 100.0
2 spacetime 32.47
3 neutron_star 31.17
4 general_relativity 24.17
5 galaxy 23.75
6 event_horizon 23.38
7 white_dwarf 22.08
8 Stephen_Hawking 22.08
9 dark_matter 20.78
10 gravitation 20.78
11 neutrino 20.78
12 quantum_gravity 19.48
13 pulsar 19.48
14 astrophysics 19.48
15 Big_Bang 19.42
16 quantum_field_theory 18.18
17 matter 17.92
18 supernova 17.48
19 Monthly_Notices_of_the_Royal_Astronomical_Society 17.2
20 dark_energy 16.88
21 solar_mass 16.88
22 elementary_particle 16.88
23 special_relativity 16.83
24 star 16.04
25 string_theory 15.58
26 Standard_Model 15.58
27 gravitational_constant 15.58
28 photon 15.54
29 gravity 15.5
30 universe 15.44
Enter table row number, or wikipage: 25
----------------
wikipage: string_theory
pattern: |10f49f> + |5bf012> + |21188d> + |7ef2ca> + |bf1c18> + |b9dd13> + |2a092d> + |0166e5> + |e06e72> + |10f129> + |745049> + |ff2ac9> + |bc58c1> + |5c3d64> + |471066> + |3e4bfb> + |c266af> + |81249b> + |b032fd> + |1266a1> + |80153f> + |483336> + |d43833> + |1f252d> + |75030e> + |c50e18> + |0ff36f> + |84cbb6> + |2a9cc1> + |8a4178> + |45b55a> + |8f25ec> + |dbe144> + |008ea6> + |be6128> + |3e34b6> + |a4fc1e> + |9cf44e> + |f84a1a> + |cc5274> + |f41208> + |1da685> + |22bdaa> + |2b6101> + |c4e210>
pattern length: 45
----------------
1 string_theory 100.0
2 quantum_gravity 40.0
3 Standard_Model 36.73
4 quark 32.08
5 supersymmetry 31.11
6 dark_energy 28.89
7 gluon 28.89
8 quantum_field_theory 28.17
9 theoretical_physics 27.66
10 spacetime 27.27
11 Roger_Penrose 26.67
12 theory_of_everything 26.67
13 quantum_electrodynamics 26.67
14 particle_physics 25.84
15 space 25.0
16 strong_interaction 24.44
17 John_Archibald_Wheeler 24.44
18 M-theory 24.44
19 dark_matter 22.92
20 boson 22.22
21 Steven_Weinberg 22.22
22 loop_quantum_gravity 22.22
23 fundamental_interaction 22.22
24 gravitation 22.03
25 fermion 21.15
26 general_relativity 20.83
27 Stephen_Hawking 20.55
28 gauge_theory 20
29 Minkowski_space 20
30 quantum_physics 20
Enter table row number, or wikipage: california
----------------
wikipage: California
pattern: |b0c37e> + |0a36a9> + |b97200> + |4b4d7e> + |240c6b> + |b7204b> + |48fbc6> + |a6ff5a> + ...
pattern length: 793
----------------
1 California 100.0
2 Los_Angeles 18.79
3 New_York 18.54
4 Texas 16.77
5 President_of_the_United_States 16.02
6 Massachusetts 14.88
7 San_Francisco 14.5
8 Washington,_D.C. 13.87
9 New_York_City 13.27
10 Illinois 13.11
11 Republican_Party_(United_States) 12.74
12 Florida 12.61
13 Pennsylvania 12.23
14 Democratic_Party_(United_States) 12.11
15 United_States_Senate 11.6
16 The_New_York_Times 11.22
17 Michigan 10.97
18 American_Civil_War 10.84
19 Mexico 10.84
20 Virginia 10.84
21 Nobel_Prize_in_Physiology_or_Medicine 10.59
22 Ohio 10.59
23 New_Jersey 10.47
24 Arizona 10.34
25 Chicago 10.21
26 Oregon 10.09
27 Nobel_Prize_in_Chemistry 10.09
28 Minnesota 9.84
29 Nobel_Prize_in_Physics 9.84
30 Ronald_Reagan 9.71
Enter table row number, or wikipage: Alan_Turing
----------------
wikipage: Alan_Turing
pattern: |045fbc> + |4efc96> + |c4b5ac> + |cdb6ba> + |645e2a> + |7b8d5f> + |d266e8> + |b2151a> + |c55099> + |c26306> + |762dc9> + |84782a> + |4ae48b> + |3f4cd2> + |72ee56> + |d7fa06> + |82fdb5> + |52d2f2> + |1ef969> + |64363c> + |61a732> + |b404e7> + |628dac> + |2b081b> + |923ec9> + |5853ee> + |41bd03> + |c54116> + |798d9f> + |2e9ea3> + |afe718> + |bb5349> + |4cb705> + |1209bc> + |d38636> + |286eaf> + |997643> + |c7ee9d> + |66c387> + |6a31a1> + |26cdc2> + |d21237> + |c939a2> + |f3fac2> + |20eb27> + |9a8319> + |82d1e3> + |33fe27> + |247805> + |0cc34a> + |5aa405> + |f88a44> + |fe443c> + |921715> + |3c10cd> + |7c0b6c> + |0c2b0a> + |a85db0> + |2ab320> + |ff3f25> + |c5e594> + |11786b> + |e14fde> + |b8866c> + |d2a848> + |933aa2> + |50316a> + |4f6b9a> + |c02ba1> + |c09ec5> + |96d4da> + |335e2a> + |210256> + |a077a1> + |cb12a0> + |a487fe> + |3a535a> + |544f2c> + |e33db4> + |468b43> + |9bb8a2> + |77756e> + |bf581a> + |70414f>
pattern length: 84
----------------
1 Alan_Turing 100.0
2 Kurt_Gdel 26.19
3 John_von_Neumann 20.69
4 Alonzo_Church 19.05
5 Bletchley_Park 17.86
6 Charles_Babbage 15.48
7 Enigma_machine 14.29
8 artificial_intelligence 14.07
9 Claude_Shannon 13.1
10 theoretical_computer_science 13.1
11 Turing_machine 13.1
12 mathematical_logic 13.1
13 David_Hilbert 13.1
14 Marvin_Minsky 11.9
15 Colossus_computer 11.9
16 cognitive_science 11.9
17 cryptography 11.7
18 formal_language 10.71
19 halting_problem 10.71
20 Alfred_North_Whitehead 10.71
21 Ada_Lovelace 10.71
22 Universal_Turing_machine 10.71
23 cryptanalysis 10.71
24 John_Searle 10.71
25 theory_of_computation 10.71
26 set_theory 10.11
27 Georg_Cantor 9.52
28 lambda_calculus 9.52
29 philosophy_of_mind 9.52
30 National_Security_Agency 9.52
Enter table row number, or wikipage: 3
----------------
wikipage: John_von_Neumann
pattern: |39ea50> + |95e32c> + |280f40> + |0cffd2> + |133177> + |352c38> + |fe1ab4> + |7bd69d> + |12dbd2> + |72f5aa> + |5001d5> + |f33c86> + |4f6b9a> + |a1dd12> + |bbf17a> + |3689f8> + |cd8d71> + |545c7c> + |40edd4> + |6c5b91> + |d2a848> + |759ba4> + |3038c6> + |880c95> + |247805> + |921715> + |35f6bd> + |f54210> + |71771d> + |a0a9c1> + |ff3f25> + |3c8b72> + |6c1d88> + |c70e25> + |c54116> + |01ae36> + |33c924> + |a077a1> + |cb12a0> + |a38825> + |22bdaa> + |2b6101> + |1c9755> + |50bf91> + |04335a> + |c55099> + |cbe282> + |f84a1a> + |72ee56> + |2c4d42> + |a38649> + |eb246d> + |cb6c0b> + |64363c> + |7975b9> + |923ec9> + |5071a0> + |8c811e> + |409b48> + |0166e5> + |a16ffc> + |b2e663> + |e14fde> + |26cdc2> + |cdb6ba> + |f80b3d> + |d43833> + |672229> + |3ad69a> + |df7e9a> + |5a9c38> + |008ea6> + |d1ce05> + |0c2b0a> + |8540a1> + |7f6407> + |3357cc> + |89b2da> + |7ed689> + |c2c6f1> + |9b29fd> + |5ba8b0> + |575d02> + |70414f> + |2161b5> + |634c4f> + |c02ba1>
pattern length: 87
----------------
1 John_von_Neumann 100.0
2 Kurt_Gdel 21.84
3 Alan_Turing 20.69
4 Werner_Heisenberg 17.24
5 game_theory 17.24
6 Niels_Bohr 16.09
7 David_Hilbert 14.94
8 Max_Born 13.79
9 Erwin_Schrdinger 13.79
10 Max_Planck 13.79
11 information_theory 12.64
12 Edward_Teller 12.64
13 Paul_Dirac 12.64
14 Manhattan_Project 11.76
15 Robert_Oppenheimer 11.49
16 Enrico_Fermi 11.49
17 probability 10.68
18 Category:Foreign_Members_of_the_Royal_Society 10.34
19 statistical_mechanics 10.34
20 Gottfried_Wilhelm_Leibniz 10.34
21 Wolfgang_Pauli 10.34
22 Los_Alamos_National_Laboratory 10.34
23 Claude_Shannon 10.34
24 mathematical_logic 10.34
25 Hans_Bethe 10.34
26 Institute_for_Advanced_Study 10.34
27 Stephen_Hawking 10.34
28 Hermann_Weyl 10.34
29 operations_research 10.34
30 Henri_Poincar 10.34
Enter table row number, or wikipage: knowledge
----------------
wikipage: knowledge
pattern: |57328a> + |1cade0> + |a2c164> + |3f45f2> + |ded1b1> + |e88da4> + |00ed19> + |f27a1e> + |4e5143> + |5b8fba> + |dd808d> + |ce7f83> + |2dd2d7> + |0597a6> + |8e72ff> + |bed3d8> + |05eb39> + |dc0ea6> + |f0bfb6> + |90f967> + |a56bee> + |d75192> + |cfe9cb> + |9d6a01> + |5cbb89> + |ef61be> + |d8cd9f> + |dc79de> + |d2e0b1> + |5238d3> + |2e00b5> + |148ecf> + |cf23e9> + |8a4178> + |d21237> + |fed2d8> + |092ffc> + |5f08dc> + |46b618> + |294cf5> + |2a6072> + |83b8cc> + |e14e23> + |7e3504> + |c808ec> + |96a0e3> + |cf8f52> + |0c2b0a> + |a85db0> + |ff3f25> + |fd9ffa> + |1477d8> + |d2a848> + |fcd820> + |f9252f> + |6fd899> + |668c81> + |0bd005> + |d3f8ad> + |ed2624> + |4d6f6d> + |a077a1> + |8c6d7c> + |7586a4> + |3a535a> + |a35319> + |99dfdc> + |188841> + |6af893> + |f8c970>
pattern length: 70
----------------
1 knowledge 100.0
2 epistemology 19.83
3 nature 18.92
4 reason 18.67
5 truth 18.57
6 mind 15.71
7 William_James 14.29
8 ontology 14.29
9 empiricism 14.29
10 Descartes 14.29
11 perception 14.29
12 Empiricism 14.29
13 Karl_Popper 14.1
14 Charles_Sanders_Peirce 13.89
15 Sren_Kierkegaard 13.7
16 John_Dewey 12.86
17 experiment 12.86
18 experience 12.86
19 theory 12.86
20 empirical 12.86
21 rationalism 12.86
22 reality 12.86
23 Ren_Descartes 11.89
24 consciousness 11.63
25 Epistemology 11.43
26 fact 11.43
27 philosophy_of_mind 11.43
28 cognitive_science 11.43
29 neuroscience 11.43
30 idealism 11.43
Enter table row number, or wikipage: love
----------------
wikipage: love
pattern: |886dc0> + |b61f68> + |f0bfb6> + |abe3e9> + |e80af4> + |e1a113> + |a2558d> + |85c746> + |dc8653> + |c00299> + |041580> + |b97749> + |c488db> + |95471f> + |048171> + |a13607> + |e71ed4> + |9a4e5a> + |245b0d> + |bb8a1b> + |6a39ef> + |0fddfd> + |69197a> + |a35319> + |a2be34> + |ab5578> + |7cbcd7> + |3220b7> + |2877db> + |8fcda4> + |b2f462>
pattern length: 31
----------------
1 love 100.0
2 fear 12.9
3 happiness 12.9
4 motivation 11.76
5 Daniel_Dennett 10
6 Al-Farabi 9.68
7 anger 9.68
8 friendship 9.68
9 John_the_Evangelist 9.68
10 olfaction 9.68
11 hope 9.68
12 logos 9.68
13 awareness 9.68
14 limbic_system 9.68
15 feeling 9.68
16 Personality_psychology 9.68
17 emotion 8.7
18 Brahman 8.57
19 neuroscience 8.51
20 Atonement_in_Christianity 7.69
21 idealism 7.5
22 cognitive_science 7.32
23 reason 6.67
24 cognition 6.67
25 Averroes 6.52
26 secular_humanism 6.45
27 Hackett_Publishing 6.45
28 Heaven_(Christianity) 6.45
29 Theory_of_Forms 6.45
30 anomie 6.45
Enter table row number, or wikipage: 17
----------------
wikipage: emotion
pattern: |a387d6> + |0f7858> + |eaee0f> + |4ade23> + |2e1fb7> + |fdc3fd> + |6c0414> + |e95f90> + |996558> + |fdf2e7> + |12223e> + |c4167a> + |0d744a> + |dc0ab0> + |e12a12> + |0f5be9> + |b62879> + |e5ee5a> + |69197a> + |3ffea4> + |85c746> + |7e8cd5> + |883680> + |f0bfb6> + |96dba7> + |35c74d> + |f1d687> + |dfab09> + |19f554> + |2d2b41> + |ddf188> + |834b10> + |d7125e> + |dbfcca> + |049195> + |0c2b0a> + |7911e1> + |6261f9> + |cdd6f9> + |8429b8> + |31f076> + |737ab3> + |a35319> + |5d273d> + |312b37> + |cef78a>
pattern length: 46
----------------
1 emotion 100.0
2 perception 24.07
3 cognition 21.74
4 mind 17.74
5 thought 17.39
6 memory 16.67
7 behavior 15.22
8 motivation 15.22
9 cognitive_science 13.04
10 reality 13.04
11 psychotherapy 13.04
12 virtue 10.87
13 evolutionary_psychology 10.87
14 imagination 10.87
15 anger 10.87
16 Brahman 10.87
17 lesion 10.87
18 human_behavior 10.87
19 attention 10.87
20 cognitive_neuroscience 10.87
21 creativity 10.87
22 hippocampus 10.87
23 intelligence 10.87
24 awareness 10.87
25 Category:Emotions 10.87
26 feeling 10.87
27 happiness 10.87
28 anxiety 10.61
29 social_science 9.68
30 ritual 9.62
Enter table row number, or wikipage: science
----------------
wikipage: science
pattern: |d5c0cb> + |005999> + |a4dd79> + |4b4d7e> + |957ba7> + |01f3a7> + |c50366> + ...
pattern length: 221
----------------
1 science 100.0
2 biology 21.68
3 philosophy 20.63
4 engineering 17.19
5 scientific_method 17.19
6 religion 16.37
7 psychology 15.84
8 physics 15.03
9 economics 14.93
10 medicine 14.03
11 chemistry 13.62
12 technology 13.57
13 Isaac_Newton 13.56
14 logic 13.12
15 Aristotle 12.81
16 ethics 12.22
17 Immanuel_Kant 11.76
18 history 11.31
19 astronomy 11.16
20 evolution 11.11
21 Plato 10.89
22 sociology 10.86
23 theology 10.86
24 Charles_Darwin 10.57
25 art 10.41
26 quantum_mechanics 10.08
27 Karl_Popper 9.95
28 epistemology 9.95
29 Albert_Einstein 9.63
30 Ren_Descartes 9.5
Enter table row number, or wikipage: DNA
----------------
wikipage: DNA
pattern: |5822da> + |ea8418> + |26c813> + |c06420> + |431b1f> + |2072d0> + |4cf7a5> + |fcd7d4> + ...
pattern length: 377
----------------
1 DNA 100.0
2 protein 31.56
3 RNA 27.32
4 bacteria 19.63
5 amino_acid 18.3
6 enzyme 17.77
7 oxygen 16.12
8 gene 15.92
9 genome 15.38
10 Nature_(journal) 14.85
11 evolution 14.85
12 cell_(biology) 14.59
13 eukaryote 13.79
14 hydrogen 12.2
15 molecular_biology 11.94
16 species 11.94
17 biochemistry 11.14
18 Science_(journal) 11.14
19 organism 11.14
20 genetics 11.14
21 virus 10.88
22 nucleic_acid 10.61
23 metabolism 10.61
24 mutation 10.61
25 polymer 10.08
26 adenine 9.81
27 nucleotide 9.81
28 carbon_dioxide 9.81
29 molecule 9.55
30 chromosome 9.28
Enter table row number, or wikipage: Tim Berners-Lee
----------------
wikipage: Tim_Berners-Lee
pattern: |ee463a> + |0a36a9> + |909162> + |35f462> + |556fc5> + |553b20> + |40ace1> + |d266e8> + |770f49> + |57b9bb> + |d8d95d> + |9e72df> + |5a576a> + |6ba526> + |7b8d5f> + |00d231> + |ef2628> + |189b17> + |434f12> + |d8fc0d> + |d0bb87> + |90f130> + |6d3e37> + |8831ba> + |e23565> + |be9708> + |09d59b> + |395a2d> + |1626d2> + |d2aac8> + |26cdc2> + |1209bc> + |0f7c6c> + |520178> + |bd1488> + |b9ea7a> + |c96252> + |33fe27> + |b03400> + |6a57a4> + |f898c2> + |445704> + |d7beb8> + |6a3f0c> + |2e5f4c> + |b9de4b> + |4a7e62> + |21d730> + |6e14c2> + |949fd1> + |519ba7> + |263003> + |d9cead> + |fce081> + |70414f>
pattern length: 55
----------------
1 Tim_Berners-Lee 100.0
2 hypertext 29.09
3 World_Wide_Web_Consortium 29.09
4 World_Wide_Web 20.93
5 Cascading_Style_Sheets 20.0
6 CERN 20.0
7 Vannevar_Bush 18.18
8 hyperlink 16.36
9 Hypertext_Transfer_Protocol 16.36
10 XHTML 16.36
11 web_browser 15.84
12 HTML 15.65
13 File_Transfer_Protocol 14.55
14 WorldWideWeb 14.55
15 W3C 14.55
16 Netscape 14.55
17 ARPANET 14.55
18 web_server 14.55
19 HTTP 13.56
20 Internet_Engineering_Task_Force 12.86
21 wiki 12.73
22 Request_for_Comments 12.73
23 TCP/IP 12.73
24 Internet_Explorer 12.73
25 Robert_Cailliau 12.73
26 Web_search_engine 12.73
27 Ted_Nelson 12.73
28 IP_address 12.73
29 Domain_Name_System 12.73
30 markup_language 12.73
Enter table row number, or wikipage: q
Perhaps I should try to explain a little of what the code is doing. So, you start with the exact title of a wikipedia page. Frequently I have to use google to find the one I'm after. Then the code converts that to a wikivec using a straight key lookup in a hash-table/dictionary.
pattern = sw_dict[wikipage]
Then it uses my similarity metric to search the entire dictionary worth of wikivec patterns, and returns the most similar:
# clean superposition version:
def faster_pattern_recognition(dict,pattern,t=0):
result = []
for label,sp in dict.items():
value = faster_simm(pattern,sp)
if value > t:
result.append((label,value))
return result
# find matching patterns:
result = faster_pattern_recognition(sw_dict,pattern)
Finally, it sorts the result, keeps the best 30 results, and then pretty prints it in table form.
But what if you don't know the exact wikipage, and don't want to google it all the time? Well, we use our pattern recognition code again, this time against letter ngrams. First, we have this code that converts a string to a letter-ngram superposition:
def process_string(s):
def create_letter_n_grams(s,N):
for i in range(len(s)-N+1):
yield s[i:i+N]
r = superposition()
for k in [1,2,3]:
for w in create_letter_n_grams(s.lower(),k):
r.add(w)
return r
Then we create a guess-dictionary, which is a mapping of the wikivec keys to these letter ngram superpositions:
def load_sw_dict_into_guess_dict(sw_dict):
dict = {}
for key in sw_dict:
dict[key] = process_string(key)
return dict
Now, what does this thing look like? Here are a couple of entries in the guess-dict:
|dog_paddle> => |a> + |_p> + |pa> + |e> + |o> + |pad> + |dl> + |dd> + |_pa> + |do> + |le> + |og> + |ddl> + |dle> + |g_> + |g_p> + |add> + |p> + |og_> + 3|d> + |_> + |ad> + |g> + |l> + |dog>
|podium> => |um> + |pod> + |di> + |i> + |iu> + |o> + |od> + |p> + |po> + |odi> + |m> + |diu> + |u> + |d> + |ium>
|Lists_of_mammals_by_region> => 2|a> + |e> + |ts_> + |by> + |_ma> + |f_> + |_m> + |ts> + |y> + 2|ma> + |st> + |_b> + |by_> + |ls> + |_by> + 2|i> + |al> + |y_r> + |als> + |reg> + |mm> + |_r> + 3|s> + |egi> + 2|s_> + |ls_> + |y_> + 4|_> + 3|m> + 2|l> + |ist> + |b> + |gi> + |of_> + |is> + 2|o> + |mma> + |mal> + |of> + |s_b> + |lis> + |gio> + |_re> + |am> + |ion> + |t> + |li> + |r> + |_o> + |eg> + |on> + |n> + |sts> + |f> + |amm> + |io> + |_of> + |mam> + |g> + |s_o> + |re> + |f_m>
Finally we have the guess-ket function. You feed it a string, and it outputs the best matching key in the guess-dictionary. In this case, if you feed in a string, it will output the title of the wikipage that most closely matches that string:
# find the key in the dictionary that is closest to s:
def guess_ket(guess_dict,s):
pattern = process_string(s)
result = ''
best_simm = 0
for label,sp in guess_dict.items():
similarity = fast_simm(pattern,sp) # can't use faster_simm, since some coeffs are not equal 1
if similarity > best_simm:
result = label
best_simm = similarity
return result
So we have two levels here. If the input to wikivec-similarity.py is not an exact wikipage title, we first run it through guess-ket (a tweak on our pattern-recognition code), and it spits out the best matching wikipage title. Then that is fed in to the pattern recognition code and returns the top 30 closest wikipages based on their wikivec similarity.
Unfortunately guess-ket is a bit on the slow side, taking roughly a minute. Presumably if I used standard edit distance etc, that spell-check engines use, we should be able to make it faster. But that kind of defeats the point of this post. The point is to make use of our superposition pattern recognition code, over two distinctly different superposition types.
A final note is that this post was motivated by the
word2vec cosine similarity results. Though our wikivec's don't seem to have the nice vector composition properties of word2vec. I quote:
It was recently shown that the word vectors capture many linguistic regularities,
for example vector operations vector('Paris') - vector('France') + vector('Italy')
results in a vector that is very close to vector('Rome'),
and vector('king') - vector('man') + vector('woman') is close to vector('queen')
Whew! That's it for this post.