In our notation, we can find actors Kevin Bacon numbers using something like:
kevin-bacon-0 |result> => |actor: Kevin (I) Bacon> kevin-bacon-1 |result> => actors movies |actor: Kevin (I) Bacon> kevin-bacon-2 |result> => [actors movies]^2 |actor: Kevin (I) Bacon> kevin-bacon-3 |result> => [actors movies]^3 |actor: Kevin (I) Bacon> kevin-bacon-4 |result> => [actors movies]^4 |actor: Kevin (I) Bacon> ... and so on.And visually looks something like this:
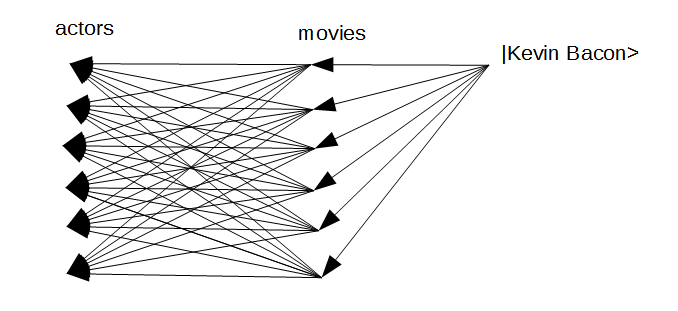
So, easy enough in theory but too slow to do that directly, so we drop back to using file_recall().
The python is not too hard:
# a single layer of the Kevin Bacon game.
# one is a superposition (though should handle kets too)
# returns a superposition.
#
# the code does:
# actors movies SUPERPOSITION
# eg:
# actors movies |actor: Kevin (I) Bacon>
#
def Kevin_Bacon_game(bacon_file,one):
if type(one) == str: # make sure we have a superposition,
one = superposition() + ket(one) # even if fed a string or a ket
elif type(one) == ket: # Hrmm... there has to be a neater way to write this mess!
one = superposition() + one
# one = one.apply_sigmoid(clean) # optional to clean coeffs from our incoming sp
sp1 = superposition()
for x in one.data:
sp1 += file_recall(bacon_file,"movies",x)
sp2 = superposition()
for x in sp1.data:
sp2 += file_recall(bacon_file,"actors",x)
print("len:",len(sp2))
return sp2.coeff_sort()
sw_bacon_file = "sw-examples/improved-imdb.sw" # our imdb data
r = ket("actor: Kevin (I) Bacon") # NB: we can choose any actor we like! We have the whole imdb to choose from!
N = 2 # How deep we want to go. For now 2, but maybe 4 or bigger later!
for k in range(N):
r = Kevin_Bacon_game(sw_bacon_file,r)
C.learn("kevin-bacon-" + str(k + 1),"result",r)
name = "sw-examples/kevin-bacon.sw" # save the results.
save_sw(C,name)
Indeed, even that might be too slow. So another optimization, we write to disk as we go:
# let's write a version that writes to disk as it goes.
sw_bacon_file = "sw-examples/improved-imdb.sw" # our imdb data
sw_dest_file = "sw-examples/fast-write--kevin-bacon.sw" # where we are going to save the results
dest = open(sw_dest_file,'w')
# write the context header:
dest.write("|context> => |context: Kevin Bacon game>\n\n")
r = ket("actor: Kevin (I) Bacon") # NB: we can choose any actor we like! We have the whole imdb to choose from!
N = 2 # How deep we want to go. For now 2, but maybe 4 or bigger later.
for k in range(N):
r = Kevin_Bacon_game(sw_bacon_file,r)
dest.write("kevin-bacon-" + str(k+1) + " |result> => " + r.display(True) + "\n") # r.display(True) for exact dump, not str(sp) version.
dest.close()
And here is the resulting kevin-bacon.sw file.Now, a couple of notes:
1) superposition += is O(n^2) or something! This is because superpositions are (currently) lists, and when you add a superposition to a superposition you have to walk the entire list checking if those kets are already in the list. Anyway, that is why I'm thinking of swapping superpositions to ordered dictionaries (note we can't use standard dictionaries because we do want to keep some sense of order even if technically kets in superpositions commute). Anyway, this is a big problem all over the place, and I've been writing hacks (eg, one of those hacks is working with dictionaries, and then when finished map that to a superposition, this drops it back to O(n) and makes a massive speed difference) to step around it for ages now. So how big of a problem is it? Well, in the current case N = 1 took 1 minute, N = 2 took 12 days! So we haven't even tried for bigger N.
2) Turns out that the number of pathways between Kevin Bacon via [actors movies] to an actor, somehow selects out well known actors. Not sure if that is because I used an older imdb data set that didn't fully filter out TV shows, and in particular award shows (that over represent well known actors), or if it is a more general thing. Anyway, this should show what I mean:
$ grep "^kevin-bacon-1 " ec2-fast-write--kevin-bacon.sw | sed 's/=> /\n/g' | sed 's/ + /\n/g' | head -30 kevin-bacon-1 |result> 182.0|actor: Kevin (I) Bacon> 30.0|actor: Kyra Sedgwick> 22.0|actor: Tom Hanks> 15.0|actor: Meryl Streep> 15.0|actor: Tina Fey> 14.0|actor: George Clooney> 14.0|actor: Drew (I) Barrymore> 13.0|actor: Clint Eastwood> 12.0|actor: Sandra Bullock> 12.0|actor: Alec Baldwin> 12.0|actor: Steve Carell> 12.0|actor: Laurence Fishburne> 12.0|actor: Brad Pitt> 12.0|actor: Kevin Spacey> 11.0|actor: Leonardo DiCaprio> 11.0|actor: Kiefer Sutherland> 11.0|actor: Amy Poehler> 11.0|actor: Tom Cruise> 11.0|actor: Michael (I) Douglas> 11.0|actor: Tim (I) Robbins> 10.0|actor: Morgan (I) Freeman> 10.0|actor: Candice Bergen> 10.0|actor: Eva Longoria> 10.0|actor: Matt Damon> 10.0|actor: Susan Sarandon> 10.0|actor: Hugh Laurie> 10.0|actor: Mark (I) Wahlberg> 10.0|actor: Glenn Close> 10.0|actor: Jennifer Love Hewitt> $ grep "^kevin-bacon-2 " ec2-fast-write--kevin-bacon.sw | sed 's/=> /\n/g' | sed 's/ + /\n/g' | head -30 kevin-bacon-2 |result> 58714.0|actor: Kevin (I) Bacon> 41662.0|actor: Tom Hanks> 29505.0|actor: Meryl Streep> 28364.0|actor: Steven Spielberg> 27638.0|actor: George Clooney> 27622.0|actor: Nicole Kidman> 25941.0|actor: Michael (I) Douglas> 25214.0|actor: Alec Baldwin> 24562.0|actor: Tina Fey> 24535.0|actor: Samuel L. Jackson> 23908.0|actor: Clint Eastwood> 23795.0|actor: Dustin Hoffman> 23746.0|actor: Halle Berry> 23337.0|actor: Glenn Close> 23018.0|actor: Morgan (I) Freeman> 22977.0|actor: Brad Pitt> 22892.0|actor: Susan Sarandon> 22818.0|actor: Drew (I) Barrymore> 22574.0|actor: Kevin Spacey> 22469.0|actor: Helen Mirren> 22394.0|actor: Kyra Sedgwick> 22290.0|actor: Tom Cruise> 22033.0|actor: John Travolta> 21936.0|actor: Leonardo DiCaprio> 21578.0|actor: Sandra Bullock> 20835.0|actor: Whoopi Goldberg> 20533.0|actor: Will (I) Smith> 20262.0|actor: Jennifer (I) Lopez> 20199.0|actor: Robin (I) Williams>Again, neat! Notice how they are all well known actors. Interesting that this just fell out.
3) Quick look at how many actors are in Kevin-Bacon-k:
-- how many movies in the full imdb.sw file: $ grep -c "^actors |movie: " imdb.sw 770170 -- how many actors in the full imdb.sw file: $ grep -c "^movies |actor: " imdb.sw 2436366 -- how many actors in kevin-bacon-1: $ grep "^kevin-bacon-1 " ec2-fast-write--kevin-bacon.sw | sed 's/=> /\n/g' | sed 's/ + /\n/g' | wc -l 6244 -- how many actors in kevin-bacon-2: $ grep "^kevin-bacon-2 " ec2-fast-write--kevin-bacon.sw | sed 's/=> /\n/g' | sed 's/ + /\n/g' | wc -l 6559024) Now a comment on sw format vs a matrix representation of the same.
Consider:
kevin-bacon-1 |result> => actors movies |actor: Kevin (I) Bacon>Well, if we did the same thing using matrices, and yeah, this maps trivially to a matrix representation, it would be expensive. The input vector would be 2,436,366 long, and the [actors movies] matrix would be 2,436,366 * 2,436,366. ie, 5,935,879,285,956 elements. Ouch!
That's it for now. More imdb related in the next post!
Update: this is related: The Oracle of Bacon
No comments:
Post a Comment